-
日期: 2025-05-08 | 来源: 量子位 | 有0人参与评论 | 专栏: 华为 | 字体: 小 中 大中国媒体量子位报道:现在,跑准万亿参数的大模型,可以彻底跟英伟达Say Goodbye了。
完成此举的,正是华为!
要知道,在此之前,训练万亿参数大模型这事,是有诸多“拦路虎”在身上的。
例如负载均衡难、通信开销大、训练效率低等等。
而华为盘古团队(包含诺亚方舟实验室、华为云等)基于昇腾国产算力平台,一举攻破了上述所有的挑战——
6000+块昇腾NPU集群上完成了7180亿(718B)参数MoE模型的长期稳定训练,并通过多项突破性系统优化技术实现了显著性能提升。
这些创新大幅提高了训练效率,支撑了行业顶尖水平模型的开发!
不得不说,“国产”二字在大模型硬件上的含金量还在持续上升。
纯国产NPU,丝滑跑通准万亿参数大模型
在拆解华为一系列“黑科技”之前,我们先需要更深入地了解一下训练超大参数MoE模型背后的困难。
总体来看,在这条路上有“四大金刚”在严阵把守。
技术报告:arxiv.org/abs/2505.04519
首先就是架构参数优化难题,需在众多参数组合中探索最优配置,设计适配昇腾NPU的大规模MoE架构,实现计算资源的高效利用。
其次是动态负载均衡挑战,路由机制需要智能分配任务,避免专家资源分配不均;这种不平衡不仅会因“木桶效应”降低训练效率,更可能导致模型收敛异常,影响最终性能表现。
还有分布式通信的瓶颈,在近万亿参数规模下,token在不同计算节点间的专家流转会产生巨大通信开销,“通信墙”问题成为制约训练效率的关键因素。
最后就是硬件适配复杂度,实现MoE算法与昇腾NPU等专用AI加速器的深度协同,需要打通算法设计、软件框架和硬件特性的全栈优化,充分释放硬件计算潜力。
针对这些问题,华为的这份技术报告分别从模型架构、MoE训练分析、系统优化等方面,详细介绍了其如何见招拆招。
首先就是MoE结构选型与昇腾亲和结构优化。
团队先进行先导实验,确定了细粒度专家加上共享专家这样的范式。随后在模型选型的时候,考虑了多个方面的因素。
在计算与访存亲和方面,通过增大模型里的hidden size(隐藏层大小),同时降低激活参数量,这样不仅能提升模型的计算量,还可以降低访存量,提高了模型训练时对算力的利用率,以及推理时的吞吐量。
在多维并行亲和方面,采用数量为2的指数级的专家数量,达成了TP8×EP4超融合并行的方式。
运用TP-extend-EP技术,避免因 TP 切分细粒度专家造成MatMul(矩阵乘法)等算子的效率下降,同时使用分组 AllToAll 通信技术来减少 EP 通信所产生的开销。
在 DaVinci 架构亲和方面,将张量按照256进行对齐处理,使其能完美匹配16×16矩阵计算单元,充分释放昇腾NPU的算力。
在流水线编排亲和方面,采用PP(流水线并行)、VPP(可变流水线并行)、空层等技术,实现PP和VPP的负载均衡,减少计算资源闲置(空泡)的情况。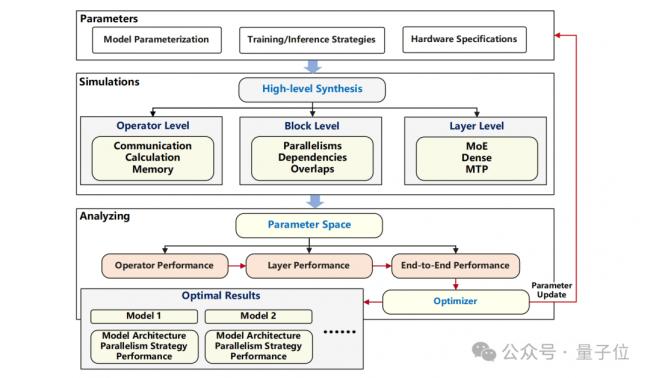
- 新闻来源于其它媒体,内容不代表本站立场!
- 告别Windows里程碑 华为首款鸿蒙电脑亮相
- 离谱 大温超800张选票就这样被忘了
- 温哥华汇款/外币兑换 汇率最优安全
- 大温Costco这样拴狗 车主遭到罚款
-
- 网友实拍温村马拉松比赛 欢乐多多
- 突发!女省长承诺2026年独立公投
- 突发!绿党反对这法案 BC或将大选
- 亚裔房东驱逐租客 被判赔偿$1.7万租金
- 周日温哥华全城大封路 有大批警力
- 这里将于周六举办盛大游行与演出
-
- 温哥华汇款/外币兑换 汇率最优安全
- 各界热评!专家:川普认为卡尼强势 值得尊敬
- 太恐怖 活蟹这样煮美食网红引众怒
- 中国深层危机:义和团式对抗无解
- 拒绝出席 三胖和普大帝闹掰了(图
- 温村这豪华公寓售价远低于12年前
-
- 中国决定"谈判" 小粉红崩溃:说好抵抗到底呢?
- 欧中建交50年:从双赢到"制度性对手"
- 川普怎么演,卡尼都稳赢!加美进入"新剧本"
- 特朗普的戏精本色 卡尼在旁边喝汤
- 90%都来自中国 他们哀嚎豁免关税
- 特斯拉销量崩盘 发布Cybercab无线充电力挽狂澜?
-
目前还没有人发表评论, 大家都在期待您的高见