-
日期: 2023-03-31 | 來源: 三聯生活周刊 | 有48人參與評論 | 字體: 小 中 大“經過這兩次大的產業升級之後,中國在數字化支付、網絡、用戶終端,基本上都和美國在同一陣線,比其他所有國家都要好。我們在最高端的計算芯片、算法系統和一些大的平台性技術方面,現在感覺到是有些距離。但我覺得中國的創業者、工程師和科研人員,一旦把資源集中,並且有耐心,是可以趕上的。有很多挑戰,但我還是充滿信心。”
記者|張宇琦
盡管中國是ChatGPT未開放服務的區域之一,但2023年2月初,在ChatGPT正式發布兩個月後,這一聊天機器人程序在中國的熱度開始走高——與之相關的話題多次登上社交媒體熱搜榜單,A股市場上ChatGPT概念股板塊歷經多番漲停潮,百度、阿裡、京東、網易等科技公司相繼宣布推出或研發對標產品的計劃。
在ChatGPT和同類產品引發持續熱議的當下,大模型技術正在觸發IT行業怎樣的變革?我們應該如何理解“中國版ChatGPT”的意義?在新一輪行業爆發期,中國AI產業會面臨怎樣的挑戰與機遇?就這些問題,本刊專訪了清華大學智能科學講席教授、智能產業研究院(AIR)院長、中國工程院院士張亞勤。
清華大學智能產業研究院(AIR)院長、中國工程院院士張亞勤(受訪者 供圖)
在學術界和工業界,以及人工智能前沿研究與產業應用領域,張亞勤都有著堪稱輝煌的履歷。他在1997年成為IEEE(電氣電子工程師學會)歷史上獲授會士榮譽最年輕的科學家;自上世紀90年代末起,曾在微軟公司工作16年,歷任微軟亞洲研究院院長兼首席科學家、微軟中國董事長等職位;在2014年9月到2019年10月之間擔任百度公司總裁。2019年底,張亞勤正式受聘於清華大學,牽頭組建清華大學智能產業研究院(AIR)。
大模型重構行業生態
三聯生活周刊:ChatGPT的出圈代表了大模型的第一次成功嗎?
張亞勤:如果ChatGPT是指的一個產品,那它是大模型產品化和大眾化的最大成功。大模型已經做了多年了,2020年GPT3.0的出現可以算是大模型的第一次成功。只不過那個模型更多是給專業人員用的,但在技術界已經有很大的震動。ChatGPT第一次有一個界面讓普通用戶使用。去年12月初,它剛剛出來的時候,我也注冊了,簡單用了一下,第一感覺是做得真好,會出很多錯,但語言能力很強,後面又看到它很大的進步。實際上,從GPT3.0到GPT3.5,做了兩年多,算法本身當然改進很多,但數據工程和系統工程尤其成功。算法裡很大的改善是InstructGPT以及多了有人類反饋的強化學習(reinforcement learning from human feedback),用的人越多,迭代越快。那麼現在GPT4就更不得了,功能比GPT3.5大多了。
但對我來說,ChatGPT更大的震撼在於它如此受歡迎!不到兩個月的時間就有了上億個月活用戶。其實生成式AI,在過去這兩年是進展最快的技術。比如在AI作圖方面,有DALL-E、Midjourney、Stable Diffusion這些產品出來。我們學院也研究這類技術,比如自動駕駛的仿真模擬,也需要在機器人裡面做生成,學生也發表了這方面的論文。總之,這個領域發展十分快,但沒有感覺跳變。
而ChatGPT確實是一次跳躍和質變,是AI的一個裡程碑。人機對話已經做了半個多世紀了,進步很大,但整體沒有實質性的飛躍,主要應用在某些垂直領域(比如聊天、客服等),整體感覺更多是玩具和工具,是個機器人,不能通過“圖靈測試”。但ChatGPT是第一個可以通過“圖靈測試”的智能體,我看到一個通用人工智能的雛形。
《她》劇照
三聯生活周刊:在整個職業生涯中,你還經歷過哪些類似的新技術爆發的時刻?
張亞勤:類似的讓我感到震撼的經歷有幾個。一次是1986年,我剛到美國的時候,第一次用了蘋果Macintosh電腦。因為之前在國內,我們最初用的還是字符型的輸入,一行一行、一閃一閃的。到了美國之後,在學校的系裡面第一次看到了帶鼠標的電腦,看到它顯示得如此之清楚、漂亮。那時就感覺到,哇,原來電腦還可以這麼做,圖形無界面,可以把鼠標放在任何地方,相當於立體化了。不僅僅能打字符,還可以用來畫圖。特別是出國前我們申請學校時,每天還在用打字機打表格,一張一張地打,感覺很困難。到了美國看到這樣一個界面,完全是一個全新的體驗。
還有一次體驗是90年代初期,那時我在Sarnoff(注:美國桑納福研究院,現SRI研究院)。當時我們在做高清數字電視,做視頻壓縮。我們第一次把所有系統集成在一起(电视剧),加上5.1的立體聲關在一個黑屋子裡,放了15分鍾SONY高清攝像機專門拍的高爾夫比賽/滑雪片段視頻,雪花和高爾夫球是那樣清晰,色彩是那樣鮮艷,大家都震撼於電視還可以這麼清楚。那時候有很多人,包括政策制定者,反對數字電視,但那15分鍾放完,大家從黑屋子裡走出來,都改變想法了。
再有就是2016年AlphaGo出來的時候。我自己也下圍棋,之前我不相信AlphaGo可以贏李世石,即使要贏,我想可能還需要至少5年左右。因為這是人類最難、最復雜的棋類,雖然我已經在做AI,我還是沒法相信它能贏了世界最優秀的九段。那次確實是第一次感受到AI的強大。
三聯生活周刊:過去相當長一段時間,科技圈似乎都在等待下一個顛覆性的技術。人工智能行業內也經歷了所謂的寒潮。現在可以說這種停滯過去了?
張亞勤:對。2016年AlphaGo讓大家都感到AI很厲害的時候,人臉識別、語音識別其實已經比較成熟,但大家仍然感覺AI只能做一件事。自動駕駛給人的感覺很酷,但一直沒變成一個主流的東西。包括搜索也用了很多AI技術,但大家可能感覺不到。總之,普通老百姓沒有感受到AI給生活帶來什麼改變。但這次大家發現,可以跟它直接對話了,它什麼都知道,雖然有時候胡說八道,有時候說廢話和套話,但人也會這樣。而且它很多地方做得比普通人要好,比如寫東西很順暢,語法也很正確,還可以幫你寫程序、規劃任務,在認知層有了很大提升,開始有了通用人工智能的雛形。
《機器紀元》劇照
我們一直在探索,哪條技術路線會走向通用人工智能。GTP3.0出來的時候,我們有一批人感覺到,大數據和超大模型可能是一個正確的方向,ChatGPT和GPT4.0+ 給大家帶來了信心。規模效應很重要。因為模型會自己進行in-context learning(上下文學習),這在規模不夠大的時候看不出效果,但到一定規模會產生一些我們不知道的現象和能力。就像互聯網,當年Metcalfe(今年的圖靈獎獲得者)定律提出,把N個人連在一塊,創造的效益是N的平方,呈指數型增長。模型的規模效益也是如此。
三聯生活周刊:大模型這條路走通後,會給整個AI行業帶來什麼?
張亞勤:我覺得可以把GPT這個系列的生成式AI模型看作一個由大模型組成的AI操作系統,和PC上的Windows,以及移動的安卓、iOS基本具有相似的意義。一個新的操作系統出來是什麼意思?下面的硬件、上面的應用都會被重構、重塑,形成一個新的生態。如果說PC互聯網的生態價值是1X,移動互聯網的生態價值至少是10X,那麼AI生態至少是100X。
在山東國瓷功能材料股份有限公司,員工用AI工業視覺識別品質檢測系統操控蜂窩陶瓷顆粒捕捉器對產品進行質量檢測(周廣學 攝 / 視覺中國)
PC時代,底層用的是英特爾的x86,在Windows上建立了許許多多的應用,也因此被叫作溫特爾(WinTel)時代。到了移動時代,Android和iOS的底層硬件都是ARM系統,上面是各種不同的APP(應用軟件)。當然,APP公司本身可能變成巨大的公司,比操作系統更大,比如微信和TikTok這樣的Super APP(超級軟件)。
到現在這個雲計算的時代,硬件有GPU、CPU、FPGA、ASIC,操作系統就是AI大模型,或許可以叫它GPTx或者基礎模型(Foundation Model,FM)。在AI還沒發展到這個階段的時候,有很多算法、模型、框架等,現在有了FM,你可以做各種各樣的應用開發:大模型上層還會有小模型,還可以有插件,和現有的APP組合在一塊。微軟目前在這方面做得最好,把能力組合到了搜索、Office和Azure雲等每一個產品。
三聯生活周刊:這樣一個新的生態,已經在很快地形成了?
張亞勤:對,但我也不認為馬上就定了。在美國的話,OpenAI和微軟搶先了一步,但是谷歌實力也很強,因為這裡面其實很多最核心的技術是谷歌發明的。微軟和谷歌這兩家公司目前可能在全球領先所有人,無論是規模效應也好,還是應用場景、算法的成熟程度和產品的生態。當然英偉達的GPU芯片和架構最有競爭力。那麼在中國的話,百度應該是走在最前面的。
三聯生活周刊:百度的CEO李彥宏在大模型產品文心一言的發布會上也提到,之前雲計算行業比拼的是廠家的算力,以後可能會更看中模型本身。
張亞勤:對,大模型變成操作系統之後,就形成了一個抽象層,開發者和用戶對下面用什麼就不太關心了。比如你現在用電腦還會在乎下面是什麼芯片嗎?無論算力多少、存儲多少,基本就被這個操作系統隔離了,你更關心的是模型能提供什麼功能。所以對雲公司來講,這也是重塑雲的時刻。
三聯生活周刊:還有一種挺普遍的看法,認為生成式對話產品會顛覆搜索引擎現有的商業模式,科技公司不得不自我革命。你也會這麼認為嗎?
張亞勤:我覺得不是。要是你沒有這個產品的話,別人會革你的命。我們在搜索的時候,其實是在找知識,那現在有了生成式技術,它確實提供了一種找到知識的新能力。所以沒辦法,新技術來的時候,一個公司說我沒有,那只能說太糟了。
但是有這個技術的話,生成本身又需要花很多錢,這也是谷歌遇到的問題。谷歌在搜索市場占有93%的份額,微軟只占3%,那3%的份額加點東西可能沒關系,93%的份額就要用很多算力,就會影響利潤。從這個角度說,所謂的顛覆市場可能是因為,我們倆做一模一樣的生意,但你谷歌的份額太高了,要比我(微軟)的成本高得多,微軟等於沒什麼可失去的。在中國的話,百度可能會有優勢,因為它正好搜索和人工智能都很強,短期裡挑戰它的公司不太多。但我想,有公司挑戰不是壞事,還是需要一些競爭的。
《機械姬》劇照
後ChatGPT時代,中國AI產業的機遇
三聯生活周刊:百度發布文心一言大模型後,吸引了大量的關注和討論。實際上,自從ChatGPT推出,很多人就在問,國內什麼時候能有一個自己的ChatGPT。中國一定需要能和ChatGPT對標的產品嗎?國內大模型中文能力更強的原因可能是什麼?
張亞勤:首先,我覺得這種多模態、預訓練的大模型,特別是基於Transformer模型的,技術還會向前演進,所以不論是產品還是系統,肯定會出現不止一個。而由於地域的區別和限制,中國會有自己的類似ChatGPT的產品,或者自己的操作系統。就像雲一樣,美國有至少5個雲,中國也有好多雲,大家都會存在。
仔細看一下,你會發現ChatGPT中文做得也很好。這點其實很有意思,因為Transformer模型一開始是用於翻譯的,在訓練的時候就用了各種不同的語言。但它不僅僅是可以用很多語言工作,還在語言映射之間找到了結構,學到了語法、語義。所以,模型被訓練的語言越多,其實會越好。如果要做中文大模型,最好裡面也有英文和其他語言。
盡管我在百度曾經做過五年總裁,但我對百度目前的產品和技術不了解,所以關於文心一言的細節你要問李彥宏。百度是在2018年就開始做這個大模型(ERNIE),在那前一年,Google發布了Transformer模型(BERT)。百度在人工智能方面的實力最強,投入時間也最長。因為做搜索和推薦最需要AI,它也做各種各樣的AI產品,比如小度、無人駕駛、智能雲,等等。所以大模型背後的技術是它必然涉及的。我認為ChatGPT的“燈塔效應”使得包括百度在內的很多公司都發力了。中國最終會有多個橫向的大模型,百度有先發優勢。
3月16日,百度公司董事長兼首席執行官李彥宏在“文心一言”發布會上發言(視覺中國 供圖)
三聯生活周刊:有人會覺得文心一言很明顯還不夠成熟,推出得有點著急。當然,模型的迭代有賴於人的反饋,很多技術上的考慮,普通人可能之前不是很了解。
張亞勤:我覺得一個產品成熟起來的最好方式,就是讓大家使用,用了之後,公司知道了反饋,相當於大家一起幫助這個產品做得更好。事實上,ChatGPT很好的一點就在於,它讓整個行業意識到,原來很多不成熟的東西大家是可以接受的。谷歌研發這個東西的時間最長,它為什麼不敢推一個產品出來?因為大公司會害怕產品不完善、會犯錯,而ChatGPT相當於提供了一個用戶的標准。包括ChatGPT為什麼是由OpenAI推出來而不是和微軟一起發布?其實微軟已經一直在產品中集成GPT4.0,看到ChatGPT用戶反饋好,微軟馬上光速推出,但它其實早就可以這麼做。但大公司有時候會因為搞不清市場的接受度在哪裡,比較謹慎。
圖 | OpenAI官網
因為我已經不在百度工作了,細節我不太知道,但我想,百度肯定是在比較之後,認為用戶應該是可以接受的。推出之後,顯然產品不完美,但是很多人會發現價值,會去使用。所以我覺得,這個推出的時間還是對的。GPT4和微軟的搜索結合起來的時候,在美國也有各種各樣的調侃。我覺得這些都正常,關鍵是要看主流是什麼,它有沒有價值。如果它有問題,也有價值,但價值大於問題,大家就會用。如果都是問題,沒什麼價值,這個產品自然而然就沒人用了。
三聯生活周刊:無論用ChatGPT還是文心一言,很多人都熱衷於比較中英文回答的差異。一些分析也提出,中文的自然語言處理可能面臨數據的局限,互聯網上中文語料的數量和質量都不如英文語料。數據會成為中國研發這類大模型的限制嗎?
張亞勤:這是個好問題。我不認為目前的模型用盡了所有的數據。現在我們生成的數據基本每一年都要翻倍,速度比摩爾定律要快,這適用於英文也適用於中文。中文語料的絕對數量可能少一些,但我不認為目前是個限制,也不認為以後會成為限制。有兩個原因。第一,可以用英文以及別的語言去訓練語言模型。第二,以後模型裡面的大部分數據未必是語言,輸入輸出都可以是多模態的,視頻、語音都可以放進去做訓練。就像我們正在講話,有語言的交互,但視覺所產生的信息量其實也很大。我們現在看到的數據很多都還是用戶自然生成的數據、機器生成的數據,但還有很多關於物理世界的數據,比如說開車,車裡產生的數據量每天是TB級別的,生物世界也產生很高量級的數據量。總之,數據量是很大的,我不認為這會是一個大的瓶頸。
但很重要的是,怎麼用好數據。ChatGPT能做這麼好,其實是在外圍花了很多工夫。數據來了之後怎麼清洗?怎樣做半監督的學習?他們做了很多這類調試,包括在肯尼亞雇了很多人做各種標注、調試,還用了剛才提到的由人類反饋的強化學習,相當於我們每次用它都在反饋。所以,除了最重要的模型訓練,這些環節也很重要。
2023年3月24日,湖北宜昌,網民展示手機上有關百度“文心一言”的信息。(圖|視覺中國)
三聯生活周刊:關於哪幾家公司會成為國內大模型的頭部玩家,現在眾說紛紜。有人說只有雲計算廠家才有足夠的算力基礎,有人說擁有超級APP的公司掌握了獨家優質數據。做大模型需要怎樣的“入場券”?在後ChatGPT時代,國內科技行業的最大機會可能在哪裡?
張亞勤:我可以畫張圖來說這個問題。ChatGPT之後,整個行業的結構會變成什麼樣。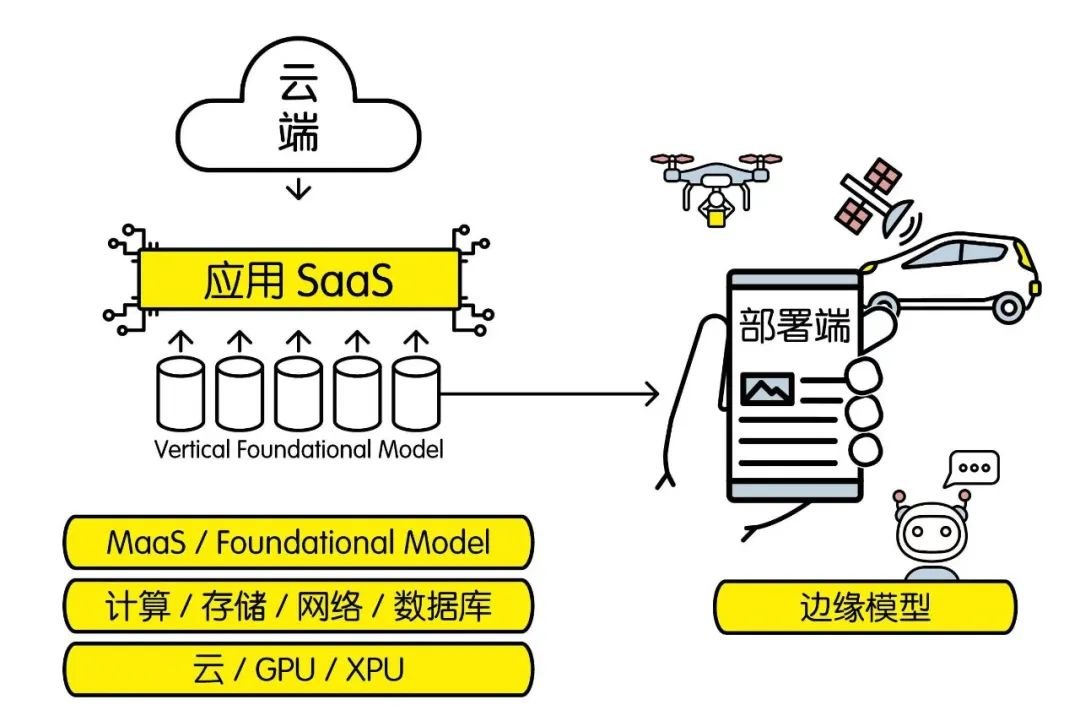
張亞勤認為,以GPT系列為代表的大模型將重塑IT行業的結構。該圖為張亞勤采訪中手繪草圖的復現
首先,最下面一層是雲,這裡面可能會有上萬個GPU(圖形處理器)或者XPU(某種處理器),表示算力。
接著往上一層是現行的IaaS(Infrastructure- as-a-Service,基礎設施即服務)操作系統,包括計算、存儲、網絡、數據、安全……
這一層上面,就是我們現在討論的基礎模型(foundational model),或者說MaaS(Model-as-a-Service,模型即服務)。
在這個上面,還會有很多垂直基礎模型(Vertical Foundational Model,VFM)。比如,自動駕駛的、蛋白質解析的、氣象預報的、面向教育的……
這些垂直模型還可以相互結合起來,再形成不同的應用,也就是SaaS(Software-as-a-Service,軟件即服務)。
那麼這樣看下來,基礎模型這一層當然是有機會,也需要具備底層才能有入場券,但其實不需要那麼多人去做這一層。大部分的機會在垂直基礎模型這一層及以上的SaaS。
同時,要在部署端(電話、個人電腦、物聯網、機器人、智能汽車等等組成的)把人工智能用上,需要做邊緣的模型部署,這一塊也存在很多工作。而且在部署端,模型不是越大越好,而是越小越好,越快越好。比如自動駕駛,你把模型部署到車的時候,不會在乎它會不會寫詩,而是要精確,在最短的時間內能把車開好,延時越短越好。邊緣的機會其實很大,所以我們現在在做邊緣計算、邊緣模型、模型交互、聯邦學習、小模型。
我覺得,可能有幾家中國公司都會做自己的系統,最有可能就是BAT(指百度、阿裡巴巴、騰訊),還有字節跳動、華為(专题)都可能做。當然,初創公司如果能拿到百億的投資也可以做,OpenAI就是這樣起來的。但我覺得,大家不一定都要一窩蜂去做操作系統這一層,主要的機會還是在上面的應用。就像手機時代,大家不能都去做安卓、iOS,不去做頭條、滴滴、淘寶了。當然,這個操作系統可能也不只有一家。
還有,同一個App也可以接入不同的系統,和不同的基礎大模型結合起來。所以我覺得以後要考慮模型和模型之間的互動,怎麼把它運用起來,在模型之間工作,怎樣在模型裡面把知識收集起來。
這樣做的一大好處是,過去做什麼應用都需要海量數據,現在很多基礎數據通過預訓練模型給你了,那麼每家就可以結合自己的專有數據做fine-tuning(精調),做prompting(提示),做這種適應就行了。之前做個公司,最怕數據不夠,因為數據散著或者在別的公司那裡。那在這個新的生態裡面,它的模型已經建好,甚至以後模型都不再需要那麼多,可能從模型裡面再抽取知識去用就可以了。
總之,我覺得有好多事可以做。ChatGPT的成功促進了整個行業的生態改變,帶來新范式,這可能才是它真正的含義。
三聯生活周刊:目前行業各部分的參與者處在什麼樣的狀態?
張亞勤:ChatGPT出來之前,GPT3.0/3.5和生成式AI已經在業界引起很大關注,但美國已經很快就形成了產品,比如做圖的DALL-E、Stable Diffusion、Midjourney,還有幫助生成文案的Jasper.ai,這些應用馬上就實現了盈收,變成真正的公司了。
圖 | OpenAI官網
在中國的話,目前也有很多這樣的公司。ChatGPT是一個信號,就是這東西行得通。所以現在中國的VC(風險投資)、高科技企業,都開始意識到這件事的重要性。反正這個月每天都有很多人找我,希望給我們學院的團隊投資,因為我們一直在從事這方面的工作。
現在大家都說想做大模型,可能只是“大模型”聽起來比較容易理解,未必是非要自己做那個平台性的大模型,而是要去做上面的應用,或者某一個垂直行業的模型。我想創業者最終都會調整好方向,找到不同的東西去做。目前大家都很興奮,每天絕對不無聊。
在基礎技術上下工夫
三聯生活周刊:在大國競爭的背景下,GPT這類技術在早期就展現出這麼強大的實力,戰略意義不言而喻。但我們在某些環節上可能受到一定限制,比如芯片的進口。你會怎麼看待這些問題?
張亞勤:這些都要考慮的。像2017年我還在百度的時候為什麼決定自己做昆侖芯片?那時就是我們所有AI任務的訓練都需要大量的算力,買的GPU太貴,供不應求,而且對我們的具體任務也不是最優的。我們就決定自己做,開始給內部業務,後來變成獨立公司。
芯片的問題是個很復雜的問題。除了設計,還有光刻機、制程、EDA等問題。我們需要在基礎的技術方面進行長期和有耐心的投入,以及扎扎實實的研發,沒有捷徑。
2021蘋果春季發布會短片劇照
三聯生活周刊:和之前幾次行業變革發生時相比,這次中國的位置有什麼不同,在積累上有什麼不一樣?
張亞勤:在PC和互聯網時代剛開始的時候,中國基本上什麼都沒有,所以全是copy to China(復制到中國)的。美國有什麼,我們copy什麼。到了移動互聯網的時代,中國在一些領域做得比美國要好,比如說5G、移動支付、微信、短視頻等。
那麼到現在,我們經過這兩次大的產業升級之後,中國在數字化支付、網絡、用戶終端,基本上都和美國在同一陣線,比其他所有國家都要好。我們在最高端的計算芯片、算法系統和一些大的平台性技術方面,現在感覺到是有些距離。但我覺得中國的創業者、工程師和科研人員,一旦把資源集中,並且有耐心,是可以趕上的。有很多挑戰,但我還是充滿信心。
三聯生活周刊:在清華大學智能產業研究院(AIR),產業內正在發生的變化會怎樣體現在工作中?
張亞勤:對我們來講,我們一直在做這事。我們沒有做那種超大規模的模型,學校做不合適,我們也不可能買上萬個A100/H100,但是我們一直在做多模態、強化學習、聯邦學習、生成技術、自動駕駛和機器人。如果說改變的話,更多的是可以假定一個大的平台已經存在了,在這個平台上,可以做更多的新研究。我們現在很多東西不再用自己做,可以用橫向的模型。實際上,我們每個團隊都在研究,怎麼能把這個東西融入到工作裡面,這兩三個月做了很多這樣的討論。對所有做研究、做產品開發的人來說,面對ChatGPT都一樣震撼,我們看到大家對AI更有信心了,整個市場,不管是投資人也好,企業也好,政府也好,都知道這個東西是這樣一個大的革新力量。我從2016年一直在講,人工智能是第四次工業革命的技術引擎,是我們這個時代最大的技術變革力量,聽的人有的信,有的不信,但現在大家都看到了AI的力量。而且AI現在所展現的只是冰山一角。
《人工智能》劇照
三聯生活周刊:你之前一直在產業的前沿,但這次的變革發生時在學院裡面,會感到稍有遺憾嗎?還是說,在如今這個位置上,可以做你更感興趣的事情?
張亞勤:其實有好多人問我,你怎麼不下場?我覺得,現在只是處在這個場的不同地方了。培養人做研究、和企業一塊創新,本來就是我這個時間想做的事。企業相當於前線,我們在後方和它們一起合作,都在“場”裡面,也感覺挺好的。而且我們現在每天都在和公司一起討論,一起規劃,一起研發。這是我們和企業合作的模式。
三聯生活周刊:這是清華大學智能產業研究院(AIR)比較獨特的模式嗎?國內的產學研結合目前處於一個怎樣的水平?
張亞勤:我覺得是因為我們與產業聯合得更緊密一些,這也是為什麼我們叫智能產業研究院。
國內產學研的結合整個做得還是不好,我也不能講美國做得有多好,但我覺得中國整體改善的空間還很大。因為大部分公司想的還是今天的產品,這樣它就覺得離“研”比較遠。如果公司很大,它能想到明天的下一代產品,甚至想到後天的產品,這個時候公司就會想到和學校合作,因為學校在做最前沿的研究。但如果你就想做今天的產品,學校也做不好,因為它不是做產品的地方。所以研究和產業自然就沒法結合好。
在美國的話,很多公司像微軟一樣,自身就有研究院,想問題會想得很長遠。還有很多制藥公司對研發投入巨大,而且會看10年之後怎麼辦,可能是因為一種藥只能占領市場10年。那麼這個時候,產學研的合作就比較容易一些。國內還是需要時間。我覺得也是自然而然有的,10年甚至5年前,都很難和國內企業合作。現在發現比原來好一些了,但是沒那麼完美,一點一點來。- 新聞來源於其它媒體,內容不代表本站立場!

- 加國華人媽媽用ChatGPT養娃 專家發警告
- "我們發財啦"! 亞裔男子喜中頭獎$8000萬
- 長周末多場暴雨 大溫僅一天有陽光
-
- 5 秒反轉、10 秒沖突:6億人沉迷,解鎖600億短劇情緒經濟
- 溫哥華地產經紀 經驗豐富誠信可靠
- 宏大可怖:格陵蘭冰層下出現異常情況
- 當心!夏季來臨這家伙又回來恐染病
- 男子退機票被收90%的手續費 律師:合規
- 大S兩個孩子不參加汪小菲婚禮原因曝光
-
- 前所未有!2萬+留學生在加拿大申請難民
- 當街槍殺兩人!加拿大全國通緝兩青少年
- 懵 溫村這裡居民想續租交百萬稅款
- 卡尼"跪"了:對美關稅近"清零" 全網怒轟
- 美中新貿易協議 美國獲5大關鍵成果
- 廣東耗資10億豪宅將被強拆 引爆輿論
-
- 大溫學區砍掉這些課?華裔家長急了
- 為酒店逃稅100萬 大溫華裔被判刑
- 美越貿易談判之際 越南豪送川普集團15億美元
- 這選區自由黨一票領先 將鬧上法庭
- 中國解禁中東力挺,波音股價飆升50%成大贏家
- 蘭裡地產專家 多年蘭裡地產經驗
-