-
日期: 2025-02-06 | 来源: 科普中国 | 有0人参与评论 | 字体: 小 中 大近日,中国“深度求索”公司发布的具备深度思考和推理能力的开源大模型 DeepSeek-R1 受到了全世界的关注。
在 DeepSeek-R1 之前,美国 OpenAI 公司的 GPT-o1,Athropic 公司的 Claude,Google 公司的 Gemini,都号称具备了深度思考和推理能力。这些模型在专业人士和吃瓜网友的五花八门的测试中,表现的确是惊才绝艳。
特别引起我们兴趣的,是 Google 的专用模型 AlphaGeometry 在公认高难度的国际奥林匹克数学竞赛中取得了 28/42 的成绩,获得银牌。学生时代我们也接触过奥数,深知能在此类国际奥赛中获银牌的选手,无一不是从小就体现出相当数学天赋,且一路努力训练的高手。能够达到这个水平的 AI,称其为具备了强大的思考能力并不过分。自打那之后,我们就一直好奇,这些强大的 AI,它们的物理水平又如何?
1 月 17 日,中科院物理所在江苏省溧阳市举办了“天目杯”理论物理竞赛。没过两天, DeepSeek-R1 的发布引爆 AI 圈,它自然成了我们测试的首选模型。此外我们测试的模型还包括:OpenAI 发布的 GPT-o1,Anthropic 发布的 Claude-sonnet。
下面是我们测试的方式:
1.整个测试由 8 段对话完成。
2.第一段对话的问题是“开场白”:交代需要完成的任务,问题的格式,提交答案的格式等。通过 AI 的回复人工确认其理解。
3.依次发送全部 7 道题目的题干,在收到回复后发送下一道题,中间无人工反馈意见。
4.每道题目的题干由文字描述和图片描述两部分组成(第三、五、七题无图)。
5.图片描述是纯文本方式,描述的文本全部生成自 GPT-4o,经人工校对。
6.每个大模型所拿到的文字材料是完全相同的(见附件)。
上述过程后,对于每个大模型我们获得了 7 段 tex 文本,对应于 7 道问题的解答。以下是我们采取的阅卷方式:
1.人工调整 tex 文本至可以用 Overleaf 工具编译,收集编译出的 PDF 文件作为答卷。
2.将 4 个模型的 7 道问题的解答分别发送给 7 位阅卷人组成的阅卷组。
3.阅卷组与“天目杯”竞赛的阅卷组完全相同,且每位阅卷人负责的题目也相同。举例:阅卷人 A 负责所有人类和 AI 答卷中的第一题;阅卷人 B 负责所有人类和 AI 答卷中的第二题,等等。
4.阅卷组汇总所有题目得分。
结果如何呢?请看下表。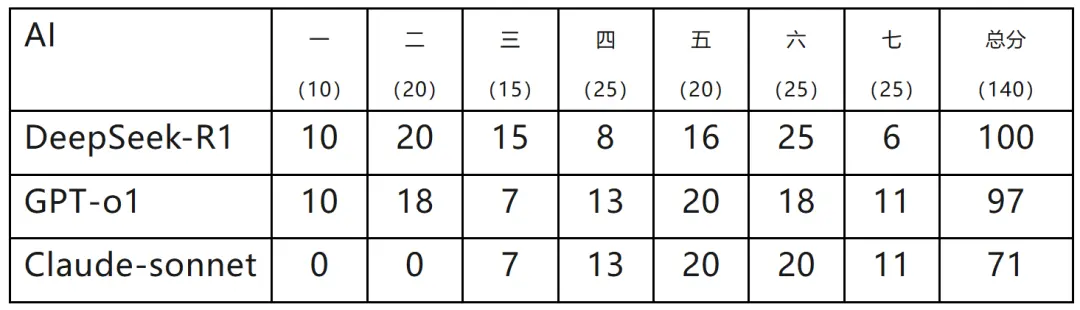
结果点评:
1.DeepSeek-R1 表现最好。基础题(前三题分数拿满),第六题还得到了人类选手中未见到的满分,第七题得分较低似乎是因为未能理解题干中“证明”的含义,仅仅重述了待证明的结论,无法得分。查看其思考过程,是存在可以给过程分的步骤的,但最后的答案中这些步骤都没有体现。
- 新闻来源于其它媒体,内容不代表本站立场!
- 问今天几月几号?DeepSeek回答笑翻网络
- 重磅 历时两年西捷终收购这家廉航
- 8964,王丹吾尔开希与李鹏对话争论点是什么?
-
- 豪猪躲飞机残骸里穿越BC近1千公里
- S家大势已去,结婚16天后马筱梅疯狂"收割",一家4口全拿捏
- 多伦多新房销售暴跌72%创历史新低
- 研究:运动能提高结肠癌生存率吗?
- 温哥华牙医诊所 提供全面牙科服务
- 逛日本集市 2天活动集美食与表演
-
- 大温华人换汇公司遭狠罚近$35万 涉9项严重违规
- 驱逐令亮绿灯 加国要迎85万难民?
- 《亮剑》李云龙攻打平安县城有多难?难怪他们伤亡会那么大
- 加国退休后还要还房贷 如何规划?
- 温哥华牙医 采用先进技术最新设备
- 陈芋汐与新搭档夺冠 全红婵现状令人唏嘘
-
- BC鹿群凶猛 狗狗在家门前遭袭惨死
- 6.4这一天,发生在中国的各种"诡异"事件
- 中国"武力夺台"迫在眉睫 美防长:恐比2027早
- 肖战《藏海传》:复仇、权谋、人性,一部剧让你爽到停不下来!?
- 藏海传:48岁的余男香肩一露,张婧仪前面的29集白演了
- 俄罗斯战略重镇惊传遇袭 核潜艇被炸
-
目前还没有人发表评论, 大家都在期待您的高见